Python Classes, namedtuples and __slots__
Data types are needed in pretty much every program that needs to store and manipulate data. These types usually have little to no behavior and simply exist to keep track of information in a structured and orderly way. Recently, PEP 557 (Data Classes) was accepted, however, it won’t appear until Python 3.7.
In this Blog Post we will explore what options currently exist in Python 2.7 and 3.6 and how they differ from each other.
Why Data Classes
Pretty much every program needs to keep track of information and structure it in some particular way so that it’s manageable. If the information that needs holding is not much, a simple tuple or dictionary may suffice. These two types are very simple and they do the job, albeit in different ways. Although they technically work, solving problems with tuples and dictionaries is a nightmare once you realize you can’t really customize instance creation/initialization or change the default behavior (easily at least). They may be good for simple cases, but it does not scale with complexity.
This is where it makes sense to have classes as data containers. You can add as much data as you please, change initialization behavior, override dunder methods, etc. Creating new classes as data containers is a good solution then (some people argue that Data Classes are bad in the grand scheme of Object Orientation, but that’s a discussion for another time), as they provide flexibility and maintainability without any apparent drawbacks.
It is important to keep in mind that class instances will store any attributes
inside a dictionary, __dict__. This means that instances will use a bit
more memory than one would expect. There’s detailed information about that in
The Python Documentation.
Introducing namedtuples and __slots__
Data Classes are fine for most cases, but Python also provides other mechanisms for holding data that slightly differ to plain classes.
namedtuples
The collections module includes the namedtuple factory function.
Calling namedtuple will simply return a new tuple subclass that allows
accessing its fields by name instead of just by index, this makes namedtuple
a step up from plain tuples. They are also memory efficient as they do do not
have a __dict__ field to hold arbitrary values. If all you need is an
immutable data container without any behavior then namedtuple might be a
better alternative to creating a new class.
namedtuples are immutable, which means that if the value of one of the fields
needs to be changed (or if it is not known at creation time) then a new
instance has to be created and all the fields copied. This also means that
inheritance will have to be used if you want to add any behavior to your newly
created types.
You can see a couple of examples of namedtuples in action in the
urllib
module as well as in the
tokenize
module.
__slots__
Using __slots__ is another option. if a __slots__ list or tuple is defined,
then a class will not have a __dict__ to store arbitrary values, thus
saving memory. Instead, only the attributes defined in __slots__ can be set.
Instances of these classes can have their attributes mutated normally and
methods can be defined as they normally would. Classes with __slots__ are
halfway between using a namedtuple and a regular class.
You can see an example of this in the
tarinfo class.
A simple benchmark
So far we have only mentioned namedtuple and __slots__ are more memory
efficient, but it’s better to actually see it in action. we will create and run
a simple script to measure memory usage, we will then plot and compare. While
the measurements we will be taking are not 100% accurate, they should be good
enough to take a look at how they all perform.
If you want to run this script yourself you will have to install psutil as a
dependency.
What should we expect to see?
The benchmark of course is not perfect as we depend on things like the garbage collector freeing memory correctly, however, what really matters for each case is how memory usage scales. Memory use will probably grow linearly, but what is really important is to take a look at the slope in each of the three cases. I expect the regular class to take a lot more memory than the other two which I expect will look pretty much the same.
Without further ado… the results!
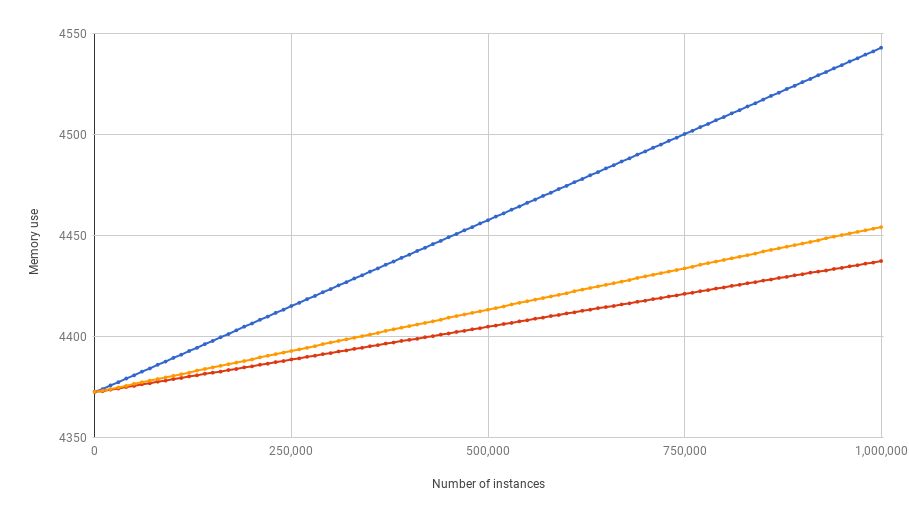
In the graph we can see the Data Class in blue, namedtuple in yellow and
__slots__ in red. As expected the three show up as lines, with regular Data
classes taking a lot more memory than instances that do not contain a
__dict__. However, what is most surprising is that namedtuple instances
take a bit more memory than instances with __slots__. If we look at the
CPython source code
and see what is happening internally, we can probably guess it is because by
default they implement some dunder methods that were not added in the example.
This however is a guess and should probably be investigated in detail to figure
out where the memory is going.
Some questions…
Using __slots__ seems pretty beneficial, however, there are some questions
that have not been answered here:
- What happens if a
__dict__attribute is added? - What happens when subclassing classes with
__slots__? What if there’s multiple inheritance in the mix? - How does this affect long term maintainability of code?
- Does this have any effect on meta classes?
There is an excellent Stack Overflow post
here that
addresses about the use of __slots__ and some of these possible caveats.
tl;dr
When needing Data Classes, if the number of objects that need to be created is
large, memory usage can be reduces drastically and easily by using namedtuples
or classes implementing __slots__.